
TA 꽈배기
rech0421k@gmail.com
TA, VR에 관심있는 지망생입니다.
[자료구조/ 알고리즘] Graph
by 꽈배기
Graph
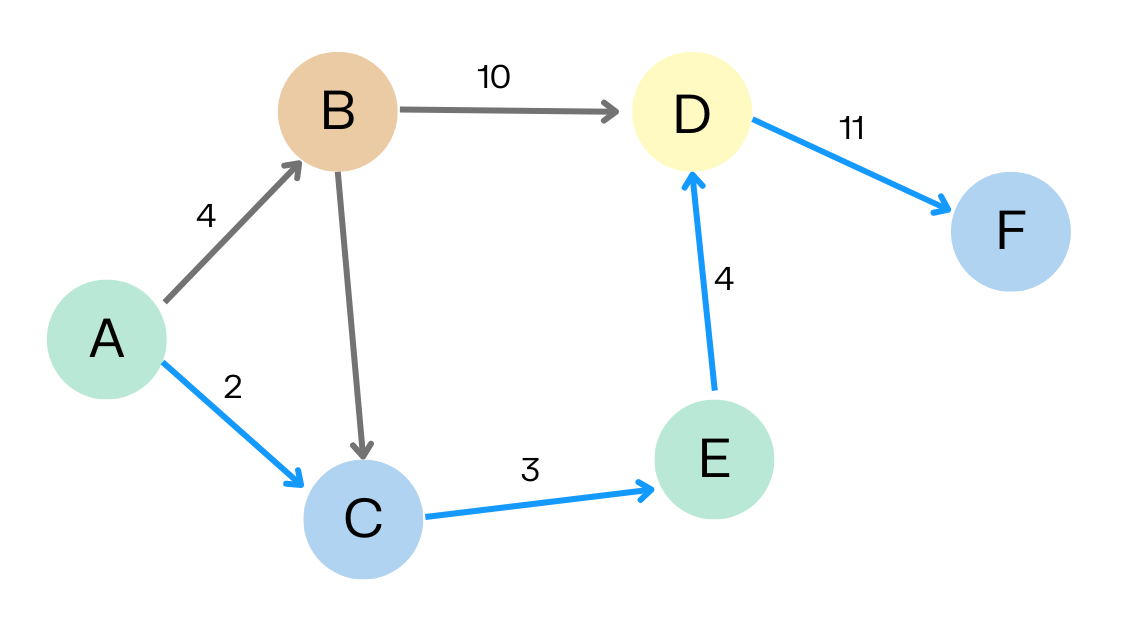
정의 및 역사
그래프는 가장자리로 연결된 노드 또는 정점으로 구성된 비선형 데이터 구조입니다. 그래프의 개념은 17세기에 레오하르트 오일러가 다리 연결성 문제를 연구하면서 처음 연구한 것으로 거슬러 올라갑니다. 하지만 20세기 중반이 되어서야 그래프가 컴퓨터 과학에서 대중적인 주제가 되었습니다.
그래프의 특징
그래프는 비선형 자료구조로 네트워크 모델 형태를 띄는 자료구조이다. 그래프의 요소로는 아래와 같은데
- Node (정점) : 데이터를 담은 개체
- Edge (간선) : 노드와 노드간의 연결 정보
- weight(가중치) : 엣지에 포함되는 가중치 (그래프에 따라 없을수도 있음)
노드는 각 노드에 따라 간선을 가질수도, 가지지 않을수도 있으며, 한 노드에서 다른 노드로 향하는 엣지가 단방향일수도 양방향일수도 있다.
장점 및 단점
그래프는 다른 데이터 구조에 비해 몇 가지 장점이 있다
- 개체 간의 복잡한 관계를 모델링할 수 있다.
- 대용량 데이터 세트 검색 및 탐색에 효율적.
- 소셜 미디어나 교통 시스템과 같은 네트워크를 표현하는 데 사용할 수 있다.
하지만 그래프에는 몇 가지 단점도 있다
- 시각화 및 이해가 어려울 수 있다.
- 다른 데이터 구조보다 더 많은 메모리를 필요로 한다.
- 올바르게 구현하지 않으면 검색 및 탐색 속도가 느려질 수 있다.
시간 복잡도
Average-case: O(logV) - 균형 검색 트리 또는 해시 테이블을 사용하여 그래프의 인접성 목록을 저장할 때.
공간 복잡도
그래프의 공간 복잡도는 그래프가 표현되는 방식에 따라 달라진다
- Adjaceny List: O(E + V)
- Adjaceny matrix: O(N^2)
- Edge List: O(E)
그래프의 데이터 저장 방법
Adjaceny List
연관되어 있는 노드들을 각 노드 기준으로 리스트 형태로 나타낸 것이다.
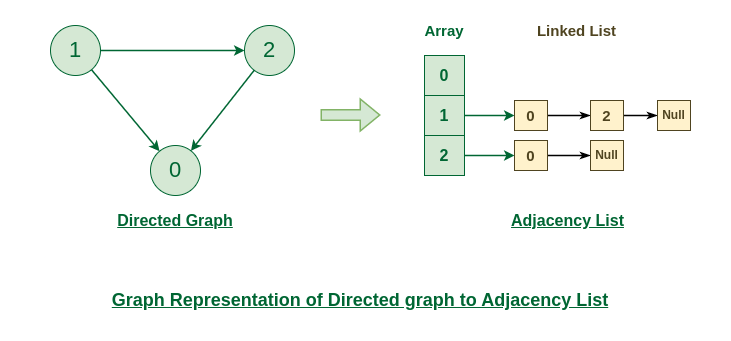
- 인접 노드끼리 저장되므로 BFS, DFS와 같은 탐색이 자주 이루어질 때 매우 유리하다
- 저장된 데이터 만큼만의 공간을 사용하므로 공간 효율성이 좋다
class Graph {
int v;
list<int>* l;
public:
Graph(int v) {
this->v = v;
l = new list<int>[v];
}
void addEdge(int i, int j, bool undir = true) {
l[i].push_back(j);
// 양방향
if (undir) {
l[j].push_back(i);
}
}
void printAdjlist() {
for (int i = 0; i < v; i++)
{
cout << i << " -- > ";
for (int node : l[i])
{
cout << node << " ,";
}
cout << endl;
}
}
};
class Node {
public:
string name;
list<string> nbrs;
Node(string name) {
this->name = name;
}
};
class Graph {
//중복을 허용하지 않는 맵 (비정렬)
unordered_map<string, Node*> m;
public:
Graph(const vector<string> & cities){
for (const string& city : cities){
m[city] = new Node(city);
}
}
//단방향 노드에 대한 엣지 추가
void addEdge(const string& city1, const string& city2, bool undir = false) {
m[city1]->nbrs.push_back(city2);
if (undir) {
m[city2]->nbrs.push_back(city1);
}
}
void printAdjList() {
for (auto& citypair : m){
Node* node = citypair.second;
//range base map 루프
for (auto it = node->nbrs.begin(); it != node->nbrs.end(); it++) {
cout << citypair.first << " : " << *it << ", ";
}
delete node;
cout << endl;
}
}
};
int main() {
vector<string> cities = {"Delhi","London","Paris","New York"};
Graph g(cities);
g.addEdge("Delhi", "London");
g.addEdge("New York", "London");
g.addEdge("Delhi", "Paris");
g.addEdge("Paris", "New York");
g.addEdge("London", "Paris");
g.printAdjList();
}
정점 또는 edge를 기준으로 자주 조회하는 경우 Adjaceny List는 인접한 정점에 상시 액세스할 수 있으므로 더 빠를 수 있다.
Adjacency Matrix
연관되어 있는 노드들을 행렬 형태로 나타낸 것이다.
- 행렬표를 통해 노드간 간선 정보를 파악할 수 있다. (가중치의 경우 가중치로도 표시된다)
- 공간을 더 많이 사용하게된다. (N x N)
- 인접노드 탐색시 인접 리스트보다 탐색이 많을 수 있어 느리다.
밀도가 높은 그래프의 모든 에지를 자주 반복해야 하는 경우 인접성 행렬이 더 효율적일 수 있다.
Edge List 각 Edge에 가중치가 부여되어 해당 가중치를 포함한 Edge 정보를 저장하는 리스트이다.
Edges = <weight, src, dest>
인접한 노드들의 정보를 저장하는 대신, 각 Edge의 관계를 가중치에 따라 저장한 방식이다.
Implicit Graph 그래프의 형태를 띄고있지 않더라도 그래프로 치환하면 그래프의 형태로 나타나게 되는것을 암시적 그래프라고 한다.
BFS
그래프 탐색 방법중 하나로 그래프의 인접 노드를 탐색하는 너비 우선 탐색이다. 주어진 소스 노드에서 시작하여 레벨별로 노드를 방문한다. 다음 레벨로 이동하기 전에 현재 노드의 모든 이웃 노드를 탐색.
#include<iostream>
#include<list>
#include<vector>
#include<queue>
using namespace std;
//BFS Breath First Search
//인접한 노드로 탐색하기에 큐로 구현된다.
class Graph {
int v;
list<int>* l;
public:
Graph(int V) {
v = V;
l = new list<int>[v];
}
void addEdge(int i, int j, bool undir = true) {
l[i].push_back(j);
if (undir) {
l[j].push_back(i);
}
}
void bfs(int source) {
queue<int> q;
bool* visited = new bool[v]{0};
q.push(source);
// 중복 노드 재탐색 금지
visited[source] = true;
while (!q.empty())
{
int f = q.front();
cout << f << endl;
q.pop();
// source를 기준으로 해당 인덱스의 인접 노드 우선 탐색
for (int& neighbor : l[f])
{
if (!visited[neighbor]) {
q.push(neighbor);
visited[neighbor] = true;
}
}
}
}
};
int main() {
Graph g(7);
g.addEdge(0,1);
g.addEdge(0, 1);
g.addEdge(1, 2);
g.addEdge(2, 3);
g.addEdge(3, 5);
g.addEdge(5, 6);
g.addEdge(4, 5);
g.addEdge(0, 4);
g.addEdge(3, 4);
g.bfs(5);
}
result : 5, 3, 6, 4, 2, 0, 1
BFS는 최단거리찾기, 연결 구성 요소 감지 알고리즘에서 가장 많이 사용된다.
- 큐에 노드가 남아있는 동안 요소를 꺼낸다.
- 꺼낸 요소의 인접 노드를 탐색하며 조건에 따라 큐 대기열에 넣고 visited를 체크한다.
DFS
깊이를 탐색하며 특정 패턴 검출, 말단 노드 탐색, 특정 경로 탐색, 모든 경로 탐색이 주이기에 스택구조를 사용한다 DFS에서는 각 브랜치를 따라 가능한 한 깊은 노드를 방문한 후 다른 브랜치를 역추적하고 탐색.
//DFS Depth First Search
//깊이를 탐색하며 전체 그래프 탐색, 말단 노드 탐색이 주이기에 스택구조를 사용한다.
void dfs(const int source) {
bool* visited = new bool[v] {0};
dfsworker(source, visited);
}
//재귀적 호출에 기반하여 작성한다.
void dfsworker(const int node, bool *visited) {
visited[node] = true;
cout << node << ", ";
for (const int& nbr : l[node]){
if (!visited[nbr]) {
dfsworker(nbr, visited);
}
}
}
int main() {
Graph g(7);
g.addEdge(0,1);
g.addEdge(0, 1);
g.addEdge(1, 2);
g.addEdge(2, 3);
g.addEdge(3, 5);
g.addEdge(5, 6);
g.addEdge(4, 5);
g.addEdge(0, 4);
g.addEdge(3, 4);
g.dfs(1);
}
result : 1,2,4,5,3,2,6
스택의 형태를 띄기에 재귀적으로 처리한다.
- 재귀적 호출을 받으면 visited를 체크한다.
- 방문하지 않은 인접 노드를 탐색하며 탐색시 해당 노드를 재귀호출한다.
Directed Acyclic Graph (DAG)
Directed Acyclic Graph는 주기가 없는 방향성 그래프. 즉, 싸이클이 없는 그래프이다. 이러한 특성으로 각 작업이 한 번만 실행될 수 있는 작업 간의 종속성을 표현하는 데 적합하다.
DAG 사용 이유
- 작업 예약: 여러 단계(예: 절단, 드릴, 페인트칠)가 있는 제조 프로세스를 나타낼 때, 토폴로지 정렬은 각 단계가 다음 단계로 넘어가기 전에 이전 단계가 완료되었는지 확인하는 데 도움이 된다.
- 종속성 관리: 소프트웨어 개발에서는 모듈이나 라이브러리 간의 종속성 문제를 식별하고 해결하는 것이 중요하다. 토폴로지 정렬은 순환 종속성을 감지하고 그에 따라 작업의 우선순위를 정하는 데 도움이 될 수 있다.
- 프로젝트 타임라인 계획: 여러 마일스톤(예: 연구, 디자인, 테스트)이 있는 복잡한 프로젝트를 계획할 때 토폴로지 정렬을 사용하면 다음 마일스톤으로 넘어가기 전에 각 마일스톤을 완료할 수 있다.
- 아사나 또는 트렐로와 같은 프로젝트 관리 도구
- Maven 또는 Gradle과 같은 소프트웨어 개발 프레임워크
- 제조 공정 제어 시스템
실생활에서의 예제
금융에서 토폴로지 정렬은 포트폴리오 최적화 또는 리스크 관리에 사용될 수 있습니다. 예를 들어, 투자 관리자는 의존성(예: 분산, 상관관계)에 따라 투자 우선순위를 정해야 할 수 있습니다.
물류 및 공급망 관리에서는 프로세스의 각 단계가 완료되었는지 확인한 후 다음 단계로 나아가는 것이 중요합니다. 토폴로지 정렬은 경로, 일정, 재고 수준을 최적화하는 데 도움이 됩니다.
생물학에서도 유전자 조절 네트워크나 단백질 간 상호작용을 이해하기 위해 토폴로지 정렬을 적용할 수 있습니다.
Topological_sort
void topological_sort() {
vector<int> indegree(count, 0);
//Iterate over all the edges to find the right indegree
//내부 차수를 구하기위해 전체 순환
for (int i = 0; i < count; i++){
for (const int & nbr : l[i]){
//i번쨰 노드가 가진 연관성을 바탕으로 nbr 노드의 차수 증가
indegree[nbr]++;
}
}
queue<int> q;
//초기 순회 노드 삽입
for (int i = 0; i < count; i++){
if (indegree[i]==0) {
q.push(i);
}
}
while (!q.empty())
{
//this node must have non dependency
int node = q.front();
cout << node << " , ";
q.pop();
//요소 pop 후에 인접 노드들의 차수를 줄임
for (const int& nbr : l[node]){
indegree[nbr]--;
if (indegree[nbr] == 0) {
q.push(nbr);
}
}
}
}
- 내부 차수를 정의한다.
- 노드 삽입 (초기 노드는 차수가 0 이므로 즉시 토폴로지 수행)
- 요소 pop후 인접 인접 노드들의 차수를 줄인다.
- 차수가 0인 요소를 넣고 2 단계부터 반복한다
이처럼 토폴로지 정렬 알고리즘은 그래프의 모든 정점의 종속성을 고려하여 방문하는 데 사용된다.
Dijkshtra (다익스트라)
다익스트라 알고리즘은 그래프나 네트워크에서 노드 간의 최단 경로를 찾는 방법으로 1959년 네덜란드의 컴퓨터 과학자 Edsger W. Dijkstra 가 고안하여 3년 후에 발표했다.
장점 및 단점
벨맨-포드나 플로이드-워샬과 같은 다른 최단 경로 알고리즘과 비교할 때 Dijkstra의 알고리즘은 몇 가지 장점이 있는데
장점
- 간단한 구현
- 두 노드 간의 최단 경로를 제공
단점
- 모든 에지 가중치가 음수가 아니라고 가정해야 한다. (구현은 가능하나, 노드 재방문을 하게되어 다익스트라의 개념이라고 보긴 어렵다)
- 시간 복잡성이 높기 때문에 밀도가 높은 그래프나 매우 큰 그래프에서는 적합하지 않다
시간 및 공간 복잡성:
다익스트라 알고리즘의 시간 복잡도는 최악의 경우 O(ElogV)이며, 여기서 E는 에지 수, V는 정점 수. 이는 각 정점에 대해 모든 에지를 반복해야 하기 때문.
다익스트라 흐름
모든 노드에 임시 거리 값 할당: 초기 노드의 경우 이 값을 0으로 설정하고 다른 모든 노드의 경우 무한대로 설정.
모든 노드에 대해 최단 경로가 결정되거나 일부 기준이 충족되면(예: 거리를 알 수 없는 노드가 더 이상 없는 경우) 알고리즘이 종료됩니다.
현재까지 거리 값이 가장 작은 노드를 선택하여 현재 노드로 설정하고 그 거리를 “노드 거리”라고 부릅니다.
현재 노드 w의 각 이웃에 대해 거리가 무한대보다 작은 노드를 선택합니다:
- 현재 노드를 통과하는 w에 대한 새로운 임시 거리를 계산합니다.
- 만약 이 거리가 현재 알려진 w의 거리보다 작으면, 거리 값과 w의 이전 정보를 모두 업데이트합니다.
class Graph2 {
int V;
list<pair<int, int>>*l;
public:
Graph2(int v) {
V = v;
l = new list<pair<int, int>>[V];
}
void addEdge(int u, int v, int wt, bool undir = true) {
l[u].push_back({ wt,v });
if (undir) {
l[v].push_back({ wt,u });
}
}
int dijkstra(int src, int dest) {
//check visited or not for distance
vector<int> dist(V,INT_MAX);
set<pair<int, int>> s;
dist[src] = 0;
s.insert({ 0,src });
while (!s.empty())
{
auto it = s.begin();
int distTillNow = it->first;
int node = it->second;
s.erase(it); //Pop from set
for (auto nbrPair : l[node]){
//해당 노드의 인접 노드 셋을 가져오기
int currentEdge = nbrPair.first;
int nbr = nbrPair.second;
// 이전 거리 + 다음 노드의 거리 < 기존 저장된 거리
if (distTillNow + currentEdge < dist[nbr]) {
auto f = s.find({ dist[nbr], nbr });
if (f != s.end()) {// 기존 set이 존재하는 경우 삭제
s.erase(f);
}
dist[nbr] = distTillNow + currentEdge;
s.insert({ dist[nbr],nbr });
}
}
}
for (int i = 0; i < V; i++){
cout << "Node i " << i << "Dist" << dist[i] << endl;
}
return dist[dest];
}
};
result:
Node i: 0 Dist 0
Node i: 1 Dist 1
Node i: 2 Dist 2
Node i: 3 Dist 4
Node i: 4 Dist 7
dest distance: 7
생각보다 bfs와 내부적으로 동일하다.
다만 bfs의 경우 가중치가 없는 그래프에서의 순회를 한다면 다익스트라는 현재 노드를 기준으로 edge의 가중치를 저장하고 있다가, 인접 노드를 순회할 때 기존 가중치와 순회중 현재 가중치를 고려하며 더 작은 값을 저장하고 노드 정보를 업데이트 한다.
tags: Algorithm, Data Structure