
TA 꽈배기
rech0421k@gmail.com
TA, VR에 관심있는 지망생입니다.
[자료구조/ 알고리즘] 해싱 알고리즘
by 꽈배기
Hash
- Key 고정된 value의 값으로 변환시킨 것이다.
- 고정된 크기의 값으로 매핑한다 (추후 크기를 늘릴 수 있다.)
- (메모리의 지역성이 연결적이단 뜻은 아니다)
- 해시값을 구하는 과정을 hashing 이라고 하며 이때 사용하는 알고리즘을 해시 함수라고 한다.
key (string) -> (hash function) -> value(numeric adress)
Hash의 특징
- search O(1)
해시 함수를 통해 key에 해당하는 value를 찾는다.
- insert O(1)
해시 함수를 통해 key에 해당하는 value를 저장한다. 이떄 데이터는 numeric adress 형식에 충돌 처리 시스템을 거쳐 저장된다.
- remove O(1)
해시 함수를 통해 key에 해당하는 value를 찾아 삭제한다. 내부구조에 따라 linked list를 순회하며 해당하는 키를 찾아 삭제한다.
Hash Function
보편적으로 사용되는 방식은
- h(key) = key % Table Size가 된다. 이때 Table Size는 소수가 되는것이 좋다.
Hash Function String weighted
예를 들어 아스키코드 형식의 a b c d를 해쉬값에 넣어 저장한다고 해보자. simple한 방식을 사용한다면 (n % table size)가 될 것이다. 다만 이럴경우 애너그램이거나, 같은 값이 추가될 경우 충돌의 우려가 많이 생길 수 있다.
추천 방식
> 소수를 선택한 뒤 지수를 높여 곱해 충돌의 가능성을 배제하는 방법이 있다.
Collision Handling
해시태이블의 충돌은 피할 수 없다.
그러므로 우리는 이를 다루는 방법이 필요하다. 좋은 해시 함수의 기준은 무엇일까?
- 최소한의 중복 (고른 분포)
- 충돌 관리능력 이들이 아마 좋은 해시 함수의 기준이 될것이다.
separate chaining
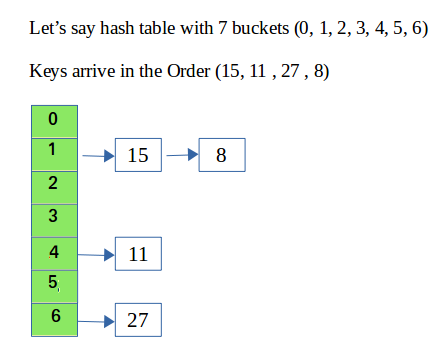
링크 리스트로 구현되어 추가 메모리를 요구함.
해쉬함수를 통해 저장된 값이 동일하다면 linked list를 통해 값을 저장한다.
open Adressing
Closed Hashing
Quadratic Probling
Double Hashing
Hashing Code
Insertion
hashing code에서 insertion은 어떻게 이루어질까?
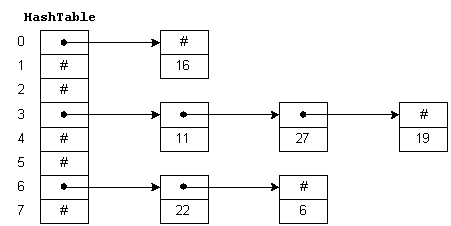
비어있는 테이블 요소는 NULL이다
- 처음 Node 개체가 해당 테이블 요소에 삽입될 시, Node의 next는 비어있는 테이블 요소를 가리키고 이는 NULL이 된다.
- 다음으로 요소가 들어올 때, n->next = table[idx] 에서 이전 노드 주소를 Node->next에 저장하고 table[idx] = n로 현재 요소의 주소가 테이블에 저장된다.
void insert(string key, T value){
int idx = hashFn(key);
Node<T> * n = new Node<T>(key,value);
//Insertion at head of the linked list
// 이전 노드의 주소를 새 요소 -> next에 저장한다.
// 테이블 인덱싱에 새 요소 주소를 저장한다.
n->next = table[idx];
table[idx] = n;
cs++;
float loadFactor = cs / (float)ts;
if (loadFactor > 0.7f) {
Rehashing();
}
}
Rehashing
만약 해시테이블의 버킷이 용량 대비 저장할 공간을 대부분 차지하게 된다면 chaining을 사용하게 될것이다.
이 과정이 반복될수록 탐색시간은 O(1) - > O(N)이 될 수 있는데, 이를 개선하기 위해 해시테이블의 용량을 키워줘야 한다.
void Rehashing() {
int oldts = ts;
cs = 0;
ts = ts * 2 + 1;
Node<T>** tempTable = table;
table = new Node<T>*[ts];
for (int i = 0; i < ts; i++)
{
table[i] = NULL;
}
for (int i = 0; i < oldts; i++)
{
Node<T>* temp = tempTable[i];
while (temp != NULL)
{
//string s = temp->key;
//T v = temp->value;
Insert(temp->key, temp->value);
temp = temp->next;
}
if (tempTable[i] != NULL) {
delete tempTable[i];
//인덱스에 연결된 노드들을 종료자를 통한 일괄 삭제
}
}
delete[] tempTable;
}
//Node
//채이닝 버킷 요소 종료자를 통한 재귀 삭제
~Node(){
if(next!= NULL){
delete next;
}
}
void Print()
{
for (int i = 0; i < ts; i++)
{
Node<T> * temp = table[i];
while (temp != NULL)
{
cout << "key : " <<temp->key << " -> ";
temp = temp->next;
}
cout << endl;
}
}
Result:
Bucket0 ->
Bucket1 -> key : water -> key : water ->
Bucket2 -> key : hamburger -> key : french fry ->
Bucket3 -> key : souce -> key : chip ->
.
.
Bucket9 -> key : coke ->
Search
문자열을 받아 테이블에 해당 정보가 있는지 탐색한다. 반환타입이 T의 포인터 형식인데, 만약 반환해야 할 값이 없을경우 NULL을 반환할 수 있도록 포인터 형식으로 감싸 반환하는것이다.
T* Search(string key){
int Idx = hashFn(key);
Node<T>* result = table[Idx];
while (result != NULL){
if(result->key == key)
return &result->value;
result = result->next;
}
return NULL;
}
string food;
cin >> food;
if (table.searching(food) != NULL) {
cout << "price : " << *table.searching(food) << endl;
}
마찬가지로 디레퍼런싱을 통해 값을 추출한다.
[] operator call by reference
연산자 오버로딩을 통해 인자값을 주소로 넘겨준다
T& operator[](string key) {
T* keyValue = searching(key);
if (keyValue == NULL) {
T obj = *keyValue;
Insert(key, obj);
keyValue = searching(key);
}
return *keyValue;
}
위와 같이 연산자 오버로딩을 해주며, 전달되는 값을 주소값으로 넘겨주면 call by reference가 된다. 이렇게 되면 어떤 차이가 있을까?
table.searching("pizza") + 20; //call by value 값이 복사 => 10
table["pizza"] += 20; // call by reference 값을 주소로 넘겨 변경된다 => 30